Manage Kubernetes addons for multiple cluster using runtime state
Video size:
Abstract
Kubernetes itself is not a complete solution. To build a production cluster, various additional addons like CNI or CoreDNS are needed. There are some solutions already. But if:
1. N Kubernetes clusters need to be managed;
2. the configuration has to change automatically when clusters runtime state changes;
we feel a new declarative solution is needed.
Given above requirements, Sveltos wants to figure out the best way to install, manage and deliver cluster addons. The idea is simple:
1. have one management cluster from where all managed clusters can be reached;
1. from the management cluster, selects one or more clusters with a Kubernetes label selector;
2. lists which Kubernetes addons need to be deployed on such clusters.
Then have a controller that automatically detects new clusters and react to configuration changes and bring cluster states to match the desired states
.
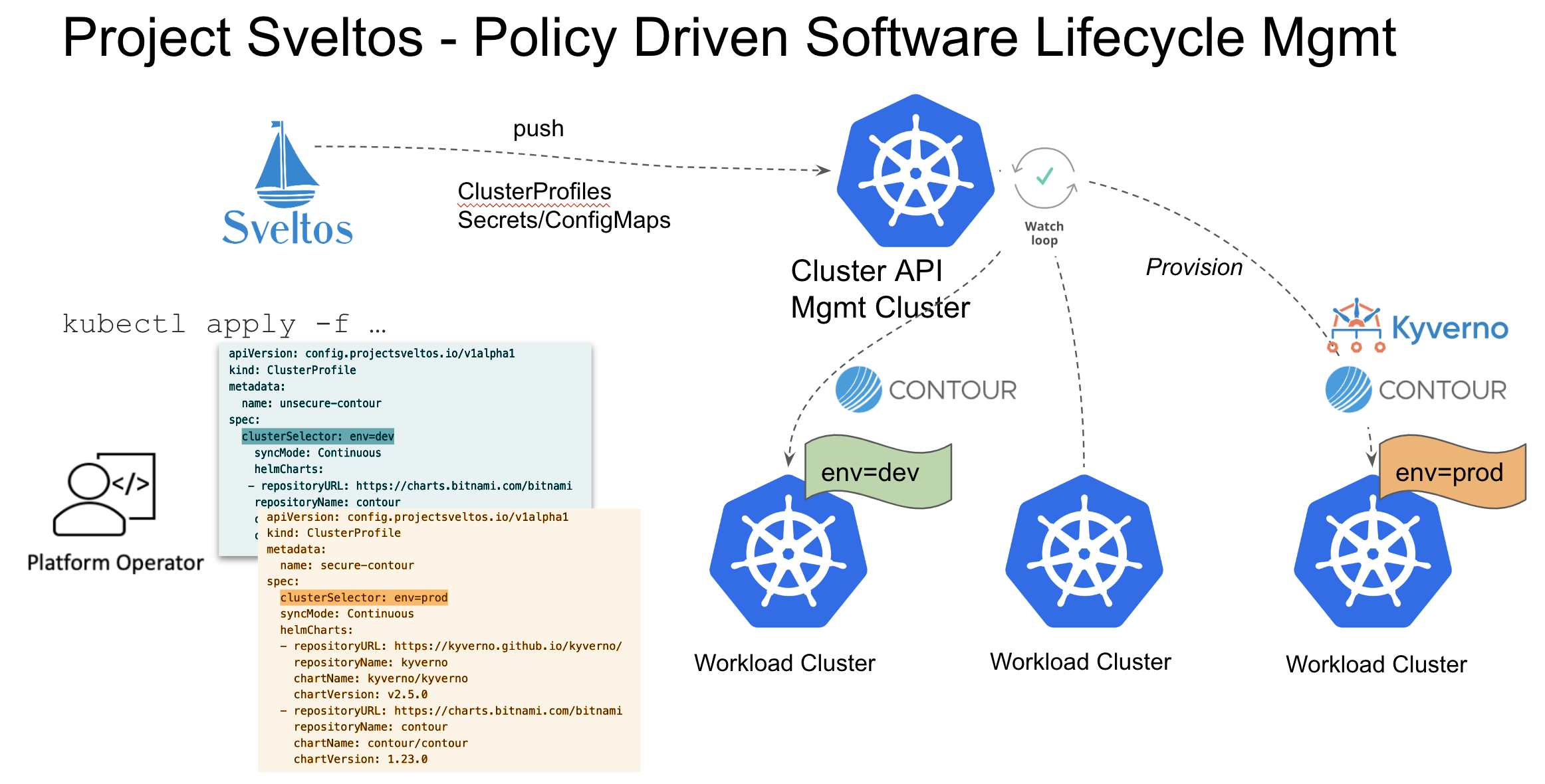 This solution needs to be able to fetch information from the management cluster. For instance, when deploying calico, pod cidrs might have to be provided. Which pod cidrs has to be used in which cluster, is usually an information present in the management cluster (in a management cluster with ClusterAPI, such information is present in the corresponding Cluster instance, in the Spec section).
This solution needs to be able to fetch information from the management cluster. For instance, when deploying calico, pod cidrs might have to be provided. Which pod cidrs has to be used in which cluster, is usually an information present in the management cluster (in a management cluster with ClusterAPI, such information is present in the corresponding Cluster instance, in the Spec section).  So far, such solution still requires user to manage cluster labels. Ideally, which labels need to be attached to a cluster should be automatically detected by looking at cluster runtime state. This is especially true for long lived clusters.
Let’s considered a very simple scenario. A set of addons (with a specific versions) are deployed in any production cluster running kubernetes version v1.24.x. When any of those clusters is upgraded to a Kubernetes version v1.25.x, a new set of addons (maybe just different versions) needs to be deployed. Instead of requiring user to change cluster labels when clusters are upgraded (which is error prone very easy to forget), we introduced a new concept: Sveltos Classifier.
Using Classifier users can classify clusters based on:
1. Kubernetes version
2. Kubernetes resources
and can define set of labels a matching cluster should have.
Using a combination of ClusterProfile and Classifier, we can have Sveltos: 1. automatically detects cluster runtime state and updates cluster labels;
- deploys new set of addons as soon as cluster is upgraded and its runtime state changes (because its labels have been updated by Sveltos as consequence of #1).
So far, such solution still requires user to manage cluster labels. Ideally, which labels need to be attached to a cluster should be automatically detected by looking at cluster runtime state. This is especially true for long lived clusters.
Let’s considered a very simple scenario. A set of addons (with a specific versions) are deployed in any production cluster running kubernetes version v1.24.x. When any of those clusters is upgraded to a Kubernetes version v1.25.x, a new set of addons (maybe just different versions) needs to be deployed. Instead of requiring user to change cluster labels when clusters are upgraded (which is error prone very easy to forget), we introduced a new concept: Sveltos Classifier.
Using Classifier users can classify clusters based on:
1. Kubernetes version
2. Kubernetes resources
and can define set of labels a matching cluster should have.
Using a combination of ClusterProfile and Classifier, we can have Sveltos: 1. automatically detects cluster runtime state and updates cluster labels;
- deploys new set of addons as soon as cluster is upgraded and its runtime state changes (because its labels have been updated by Sveltos as consequence of #1).
 When deploying N addons in M clusters, an emphasis need to be on visibility. When making a change it must be clear what effects are going to be (which clusters are going to be impacted and how).
So sveltos can be set in DryRun mode. While in DryRun mode, we can make any change and nothing will be propagated to managed cluster. Rather when done, we can use sveltos to see what would happen because of our changes and where (which clusters). Sveltos will create a summary table listing:
- which helm charts will be deployed/deleted;
- which helm charts will be upgraded (from which version to which version);
- which kubernetes resources will be updated.
After reviewing if fine with the change, Sveltos can be switched back to continuous mode and only then it will propagated changes to managed cluster.
Sveltos also supports taking snapshots and rollback of the configuration.
When deploying N addons in M clusters, an emphasis need to be on visibility. When making a change it must be clear what effects are going to be (which clusters are going to be impacted and how).
So sveltos can be set in DryRun mode. While in DryRun mode, we can make any change and nothing will be propagated to managed cluster. Rather when done, we can use sveltos to see what would happen because of our changes and where (which clusters). Sveltos will create a summary table listing:
- which helm charts will be deployed/deleted;
- which helm charts will be upgraded (from which version to which version);
- which kubernetes resources will be updated.
After reviewing if fine with the change, Sveltos can be switched back to continuous mode and only then it will propagated changes to managed cluster.
Sveltos also supports taking snapshots and rollback of the configuration.
Summary
-
Sveltos is a lightweight application that can be installed in the management cluster. It can manage kubernetes add ons in any cluster that is directly reachable from the managed cluster. Sveltos comes with built in support for cluster API.
Transcript
This transcript was autogenerated. To make changes, submit a PR.
Hello, my name is Marbente, I'm a principal
engineer at Cisco Systems. I've been working on Kubernetes
for the last five years. Today's talk is
about Sveltos. Sveltos is an open source project that I
developed which aims at simplifying kubernetes
advanced distributions. When you have tens of clusters
today, it's very easy for an organization
to have multiple clusters and to have those kubernetes
clusters in different cloud providers or infrastructures.
And when you have that many clusters consistently
managing addons, it's not a very easy task.
Sveltos is a lightweight application that can
be installed in the management cluster and that can
manage kubernetes add ons in any cluster that
is directly reachable from the managed cluster.
Sveltos comes with built in support for cluster API.
Cluster API it's another open resources project which is widely
used to consistently create upgrade urban Kubernetes clusters.
Sveltos as I mentioned has built in support for cluster API and
that means that if Sveltos is installed in a management cluster
where cluster API is also present, no action needed
to be taken. Sveltos can automatically detect
any cluster API public cluster and
manage kubernetes add ons in such cluster. But Sveltos
is not limited to cluster API. If you
have a GKE cluster Anyks cluster and you want
Sveltos to manage add ons in such clusters, you can
easily register this cluster with Sveltos and from that point
on Sveltos can seamless manage kubernetes add
ons in any cluster.
I'm not going into detail of how
to register a cluster with Sveltos.
It's a very simple procedure which is listed in the
Sveltos documentation. So please
refer to that one.
What I want to highlight here is that any cluster
it's represented in the management cluster.
So cluster API power clusters represent the management cluster
by the cluster API cluster CRD any
cluster which type GKE which is registered with Sveltos
it requirements a management cluster by Sveltos
Cluster CLD instance. So how does Sveltos
solve this kubernetes add ons distribution?
Those idea is simple. Select a subset
of the cluster that we manage and list the add ons that we have
to deploys in such clusters.
In this example I have a cluster profile inserts.
Cluster profile is one of the Sveltos crbs
and the cluster profile spec section has
two main solutions. Those is a cluster selector and
there is an l chart section. Those cluster selector
it's a pure Kubernetes label selector.
In this case this cluster profile. It's telling
us Sveltos to selects any cluster that matches that has the
label environment production and it
is also this cluster profile. It's also instructing Sveltos to
deploy Caverno L charts version 2.5.0
in any such cluster. So what
happens if we add those label environment production to
the two workflow clusters? Well, Sveltos automatically
detects that those two clusters are a match for this cluster profile
because this cluster profile is saying that the Caverno charts needs to
deploy those sveltos automatically deploys caverno
in but clusters.
Now one thing which is important is that if you
are when you deploy an elm, shark or Kubernetes
resource in many clusters, very likely
you need to customize the helm shard
per clusters. For instance, if you are deploying
calico, you need to tell Calico what the podcider
is. In this example I have a cluster
profile which is instructing Sveltos
to deploy Calico and it's
also instructing Sveltos to fetch
the podcider from those management cluster at
runtime. Runtime means at the very
exact time when Sveltos is deploying
calico in a cluster, fetch that
information. And in this case Sveltos is fetching that information reading
the cluster instance that represents the cluster and
reading the spec cluster network cyber
blocks fields.
Now let's go back to our
example. We had Sveltos deploy Caverno
in any cluster with those label environment production.
What happens if now one of the admin in
one of the managed cluster detected the Caverno
deployment. So we have one of the admin issue in
the Kubectl delete deployment and what happens that
Caverno gets deleted from the managed cluster.
But if we do that now we have a workflow cluster state.
It's different than the expected state. The expected state is what has
been defined in the management cluster. The expected state or
any cluster with label environment says that
Caverna needs to be present. As of now Cavern has
been deleted. So Sveltos has
a configuration bring detection configuration bring
detection means that there is can agent that Sveltos
installs in
each managed cluster and this agent has
one very simple prone watch any
resource which is deployed by Sveltos and if this
resource is modified, notify immediately Sveltos
running the management cluster. In this example,
Caverno was one of the resources that Sveltos developed
deployed in the managed cluster. But this resources has been deleted
by issuing a command directly in the managed
cluster. So the agent running in this managed
cluster automatically immediately detects that there is a potential
configuration grid and it informs Sveltos running the management
cluster. As soon as Sveltos is informed, Sveltos reconciled
back and by reconciling back, Caverno gets deployed back.
The state of the workload cluster goes back in sync with
the expected state defined in the management
cluster and there is absolutely no admin
intervention that is needed.
In all the example we have considered so far,
we has the management
cluster admin set the labels on the clusters,
but we are talking about managing
tens, potentially hundreds of Kubernetes clusters,
so we cannot expect those
management cluster admin to be the only one in
charge of setting the labels on each clusters.
I wanted to have like a more intent
based mechanism for that. I mean that
I wanted to be able to say if
cluster runtime state matches this,
I want this set of labels to be automatically added
to the cluster by Sveltos. Let's take an example.
So we have a cluster profile which we can ignore
for now. And we
have a classifier classifier.
It's another Sveltos CRT and those classifier
in the spec section saying it has
a Kubernetes version constraint saying if you see a cluster
running Kubernetes version between prone 24
and strictly less than 125, such a cluster is a match for
this classifier. And any cluster which is a match for this classifier
needs to have those classifier labels target. In this
case the label are simply gatekeeper v three nine.
So let's see what happens. In this example we have two clusters whose
version is 124. Two.
So they are both matching this classified. And because
they are both matching this classifier, Sveltos automatically
adds the label gatekeeper v three nine into both clusters.
And when we use a classifier in combination with the cluster file,
because now those labels, those clusters have the label gatekeeper v
three nine, they are a match for this cluster
file. And because they are a match for this cluster profile,
gatekeeper gets deployed in the cluster.
What happens now if we post another classifier
instance? Classifier instance it has a different Kubernetes
version constraint saying that any cluster running
a Kubernetes versions greater or equal than
125 is a match for this classifier. So what happens if we upgrade
one of the clusters? If one
of the cluster gets upgraded, it stops.
Bring a match for the old classifier and it starts. Bring a
match for the new classifier. Because a match for the new classifier,
the labels is updated to gatekeeper v three
because the label is updated. Now the classifier matches
different class of file and because the classifier matches different
class of the file, now a different version of gatekeeper is installed.
So the gatekeeper gets upgraded from three 90
to 3100. So combination
the classifier with a cluster profile. We can automatically
have Sveltos update the cluster labels
based on the cluster runtime states and when the
cluster labels change those cluster stop.
Matching cluster files has matching different cluster files so those set
of addons set gets deployed in the cluster changes classifier.
It's not limited to classify a cluster based on the Kubernetes version.
You can classify a cluster based on any resource.
There are many examples that you can refer to
in those Sveltos documentation.
Sveltos also has support to take snapshot.
Snapshot is another Sveltos CLD and in
this case this snapshot
instance is instructing Sveltos to take snapshots every hour.
When Sveltos takes snapshot, it takes like a snapshot of the configuration
in the managed cluster. Once you have more
than prone snapshot, you can use Sveltoscaddle
which is a CLI that I developed explicitly for Sveltos and
you can take a look at all that has changed between two snapshots.
And if there is something that you don't like,
Sveltos has also support for rolling back the
configuration. So you can start Sveltos to say you can tell Sveltos,
bring the configuration back to this snapshot instance
and Sveltos is reconciling the management cluster
configuration to the snapshot instance.
Sveltos has many other features Project
Sveltos IO it's the website with the full documentation
and there are many examples on how to register a cluster how
to classify a cluster based
on resources top of versions
GitHub.com projects
Sveltos is where all these Sveltos repos are
and as I mentioned, Sveltos is an open source project.
Any contribution is welcome. So if you have an idea,
if you want to contribute, if you want to use it and you have any
question, please feel free to reach us on slack
projectspeltoslack.com and I
will be happy to clear from you.
Thank you so much. Thank you for your time. I hope you found
this presentation useful and again, I hope you find the
a problem and the solution also a
good solution. Thank you so much.
